This week I have the flu. I moved my desk closer to the bed and… blacked out, then… binge-watched a few movies 😄 , and after that… studied a lot actually.
Some of my learning sessions felt blurry, but satisfactory nonetheless.
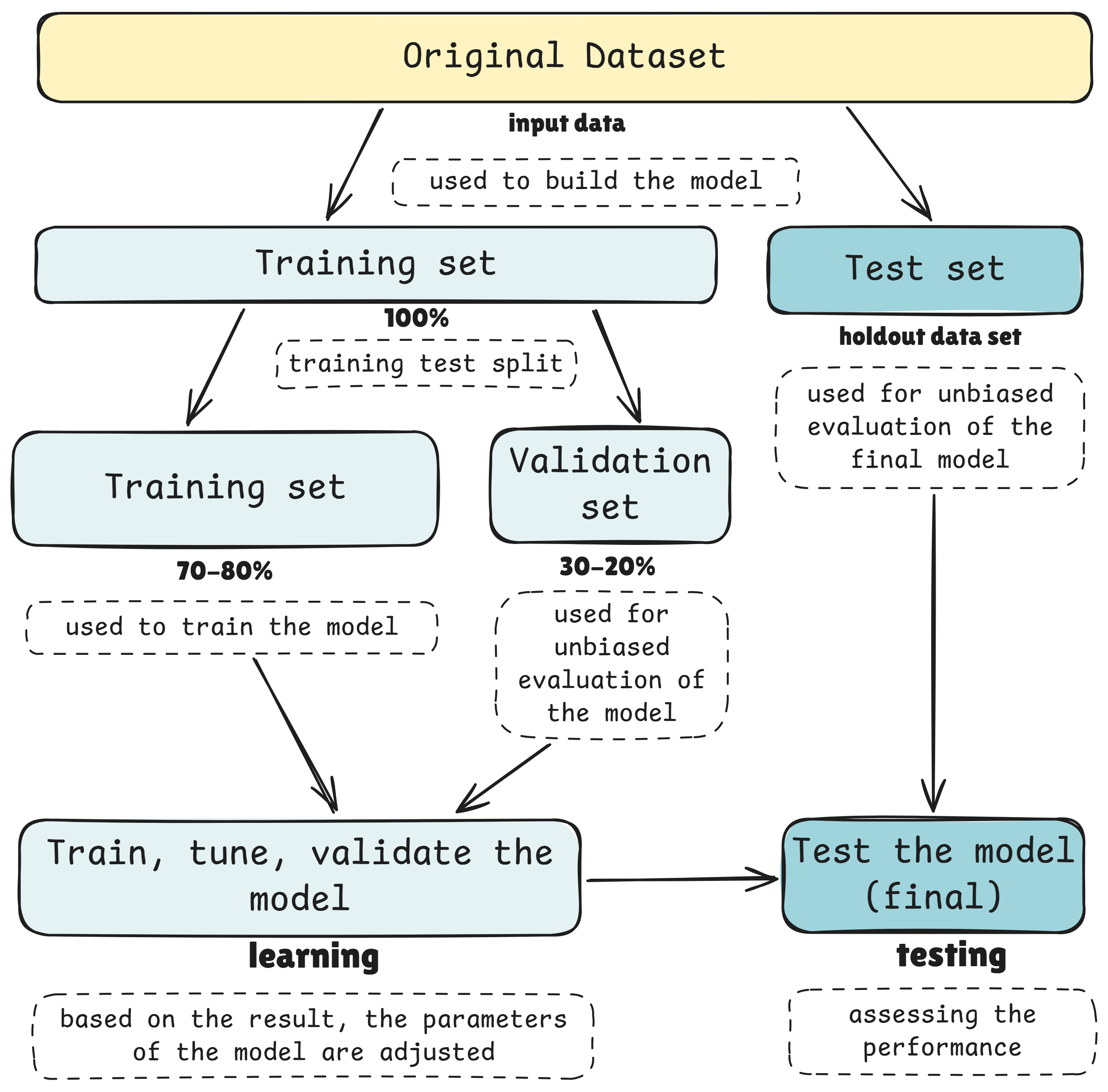
I continued with one course on Machine Learning I have recently started and there was one concept that I suppose can be confusing. How datasets for ML are used.
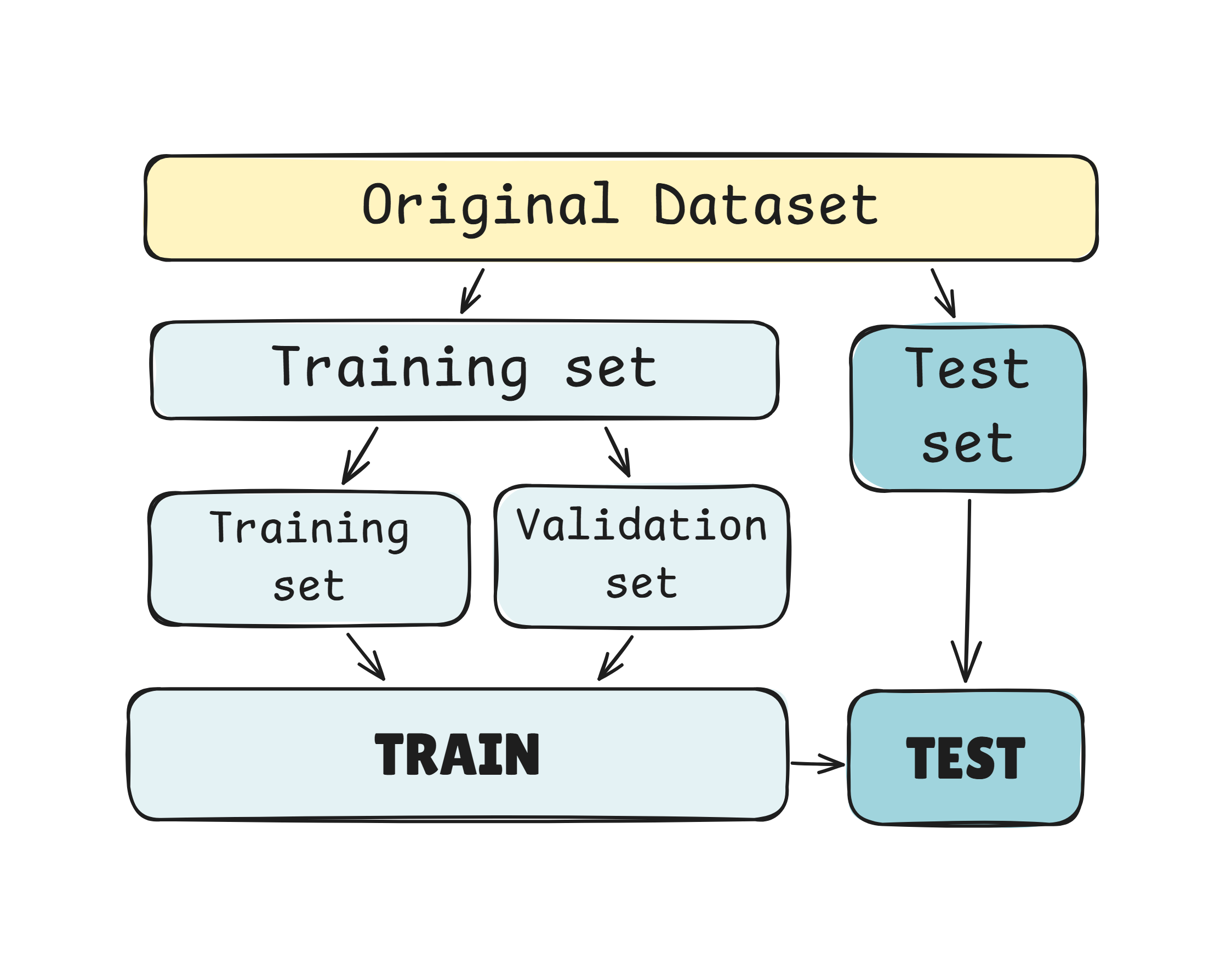
Training, validation, and test datasets are mostly associated with supervised learning. The general idea of splitting data for training, evaluation, and testing can extend to unsupervised learning in some cases and even in reinforcement learning, though the approach may differ.
All clear? 😄
So, let’s imagine we have 1,000 photos of cats and dogs.
Supervised learning: We know which photo shows a cat and which shows a dog — like having an answer key. So we can give this information to the model.
In order to test the model we could split the photos into 70% (700 photos) for training and 30% (300 photos) for testing. Those 700 we took we also split by 70-80% (490 photos) for training and 30-20% (210 photos) for validation.
Just smaller training set within main training set.
The model learns from the smaller training set, then we check how well it’s learning on the validation set, and finally test the model on unseen photos (300) to see if it really understands the difference.
Unsupervised learning: Now, imagine the photos have no labels. The model has to figure out patterns on its own — for example, grouping similar-looking animals together. We can still split the data to see if the groups it finds are consistent across sets, but there’s no “right answer” to compare against. (=no key answer we had above)
Reinforcement learning: Here, the model learns by trial and error, like training a virtual pet to fetch a ball. It tries different actions and gets feedback (rewards) based on success. You could still have different scenarios to train, validate, and test, but the process focuses on learning through interaction rather than looking at a dataset all at once.
In short:
- training is for learning,
- validation is for checking while learning,
- and testing is for a final reality check — whether the model is following instructions, discovering patterns, or learning through experience.
We trained the model using approach in the chart above, with Linear Regression and Gradient Boosting Regression algorithms.
I won’t go into the details about algorithms now, since I’m still forming the bigger picture of them. I’m excited to see how other algorithms work and whether my view of this chart will evolve over time.